データコンペ反省会
この記事はWMMC Advent Calendar 2022 の11日目の記事です。
WMMC Advent Calendar 2022 - Adventar
昨日の記事はT_Kimura氏の
「ロボット日記: DCマウスにステップアップするにあたって」
でした。
非常にためになる記事でしたね。言葉の節々に苦労したんだろうな...というのが感じられました。ただただ恐縮です。
今日の記事はマウスにまったく関係ないので、かるーく見てください。
目次
自己紹介
会計をやっているpizzagatakasugiです。そのうち成仏します。
データサイエンスコンペティションとは
あまり聞きなじみがない言葉かもしれません。
基本的にデータコンペといえば、
参加者が共通のデータセットに対して最も精度の良い予測モデルを構築する大会です。
ただし、ここでは早稲田が主催しているコンペのことを指します。
このコンペに参加しました。
kaggleやSIGNATEの最大の違いとしてプレゼンをするというものがあります。
全体的な流れとしては、
データセットが与えらえる
↓
自由に分析する
↓
得られた知見をプレゼン形式で発表する



みたいな感じです。
実質アイデアコンテストみたいなものです。
予選でグループに分かれて発表をして結果がよければ決勝に進みます。
MyWasedaに当日の動画が公開されているみたいなので、
興味があればどうぞ。
分析手法
学外の人に発表する際は許可をとらなければいけないので、
データの内容については触れません。そのため何をやったかについてだけ
ざっくり説明すると
検定における処置群と対照群で処置群のみしか得られず、処置群のデータの属性が過多で傾向スコアによるマッチングが難しかったので深層学習によりやや強引に対照群のデータを生成し、平均因果効果を求めました。
雰囲気で感じてください。
結果
しっっっっかり予選落ちしました。
割とがんばった(当社比)のでそこそこ凹みました。
というわけで以降は反省会です。
敗戦直後なのでかなりネガってます。
苦手な人はブラウザバックしてください。
結果の分析
もっとテーマ決めに時間をかければ良かった
予選敗退の原因はいろいろあると思うのですが、根本を考えるとここに行き着きます。
僕はこういう自由な設定が与えられると、つい気持ちがはやってすぐにテーマを決めて実行に取り掛かろうとするんですが、まぁこれがよくない。
自分が今所属している研究室でも研究テーマについてかなり詳細な説明をされて、
えらく丁寧に決めるんだなぁと思ってたんですが、考えが甘かった。
テーマ決めってすごい重要なんですね。
結局のところテーマが普通過ぎると、誰でも出来るというか当たり前というか
面白味みたいなものが何もないんですよね。
もっと強みを活かせば良かった
私見ですが、今データ分析は統計因果推論と機械学習に分かれている気がします。
僕は機械学習側の人間なので、もっとそっち方面に偏っていけばよかったのですが、
つい目移りしてしまってどっちもやった結果どっちも中途半端に
終わってしまいました。時と状況によると思うのですが、こういったアイデア系の
制作物は全体を網羅するよりも一方面に尖ったほうがいいです。
結果的にその方が見映えがよくなります。
世間で∞回言われているやつ
テーマの話をしたんですが、受賞チームの傾向をみたところ、
・提案した手法が新しいかどうか
・得られた結果が(正しいかどうかは分からないが)有効かどうか
を重要視しているみたいです。
要するに誰もがなんとなく知っていることとか、知ってても意味がないことは
じっくり分析してもあまり良い評価はされないということなんでしょうね。
よくよく考えてみたら
求められていないことを完璧にこなして一人で気持ちよくなっていただけでした。
終わりに
というわけでいろいろ語ってしまいました。
ただいい経験になりました。
皆さんも機会があったらどうぞ参加してみてください。
理系と文系の着目点のギャップみたいなのがわかると思います。
明日の記事はkuroさんの「1自由度振動の数値シュミレーションについて書こうかな」です。当に工学系といった感じでワクワクしてきますね。
お忙しい中ありがとうございます。
それでは
Kaggle始めました。
この記事はWMMC Advent Calendar 2021 の14日目の記事です。
https://adventar.org/calendars/6490
目次
はじめに
こんにちは。お初にお目にかかる人が多いと思います、今年WMMCに入会した情報通信学科2年のYamauchiです。昨日の記事はaosa4054さんの
「一人暮らしの酒 - 袋とじ開けたら猫がドジョウでiPad踊ってた」でした。
高レイヤーの方には不思議と親しみを覚えます。お酒は飲みたいと思ってもなかなか機会がないんですよね。いつかバーに行ってみたいと常々思ってます。
今日はKaggleの紹介?記事です。
Kaggleとは
詳しく説明するとキリがないので今回は概要だけ。
Kaggleとはデータ解析コンペサイトの一種で競技プログラミングのプログラミングがデータ解析に置き換わったようなものです。各参加者はクライアントからデータを渡されてデータの傾向や特徴をうまく説明するモデルを作成するよう指示されます。渡されるデータはテーブルデータが多いですが、画像データや音声データが渡されることもあります。コンペ中は一日に5回まで予測結果を採点することができ、最終的にスコアの良かった参加者が賞金とメダルを獲得できます。
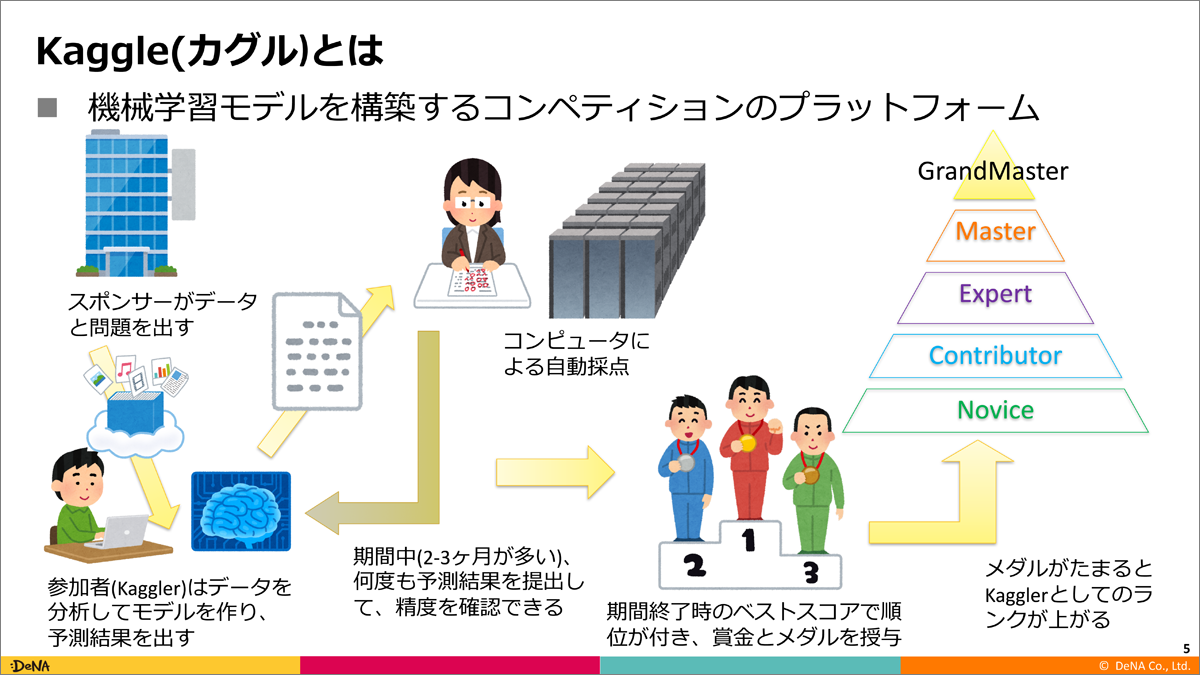
(引用: https://cz-cdn.shoeisha.jp/static/images/article/11066/11066_002.png)
){kind=link}
終了したコンペに対しても練習として、賞金とメダルはもらえませんが参加することができます。今回は初心者向けの過去コンペに参加したのでそれを記事にしました。
データ解析の様子
なんか理論とか説明しだすと (。´・ω・)ん? になるので実践に移ります。
よくわからんぞ!って人は流れで感じてください。
今回取り扱うコンペはOtto Group Product Classification Challenge(引用URL: https://www.kaggle.com/c/otto-group-product-classification-challeng
)です。Kaggle初心者ガイドの初心者お勧め過去コンペから引っ張ってきました。
引用URL:
- https://kaggler -ja-wiki.herokuapp.com/kaggle%E5%88%9D%E5%BF%83%E8%80%85%E3%82%AC%E3%82%A4%E3%83%89#%E5%88%9D%E5%BF%83%E8%80%85%E3%81%8A%E5%8B%A7%E3%82%81%E9%81%8E%E5%8E%BB%E3%82%B3%E3%83%B3%E3%83%9A
オットーグループはドイツのハイゼンベルクに本社を置く通信販売、電子商取引の企業で今回は20万個以上の製品に対して各製品がどのグループに属するのか予測するモデルを作ってほしいとのこと。早速Notebookで訓練データの中身を見ていきます。csvファイルをデータフレーム形式で確認します。

沢山数字が出てきました。
どうやらこのデータには各商品のidと93個の特徴量(おそらくは大きさや値段、生産国など)が含まれているらしく、それらから傾向をつかんでどのクラスに分類するか予測するようです。実際データの右端にはどのクラスに分類されるかの変数targetがあります。

ちなみに各特徴が何であるかや、各クラスがどういった商品なのかの説明は一切ありません。たまげたなぁ。
早速これをもとにモデルを作成していきます。
ロジスティック回帰
ロジスティック回帰は重回帰分析で得られた値をシグモイド関数に代入して所属確率を求める方法です。
やってることは単純でただロジスティック回帰をしてくれるライブラリをインポートしてそこにデータを与えて予測しただけです。設定上変数の型が数値でなくてはならないのでデータを少しいじっています。早速得られた予測値を提出してみようと思います!
↓結果はこんな感じです

スコアは出ているのですが順位表に名前がありません。
これは別に
(順位表に)おめぇーの席ねぇから!
というわけではなく過去のコンペだとリアルタイムで参加した人しか順位が出ない仕様になっているらしいです。スコアから逆算すると大体2500/3500位程度。デフォルトなのでこんなものです。
LightGBM
LightGBMは、決定木を使った手法の一つです。決定木は閾値条件によるデータの分岐を繰り返すことで、回帰や分類をします。

上の図のように条件式を満たすかどうかでクラス分けします。また、LightGBMは勾配ブースティングという手法を使っています。これは前の学習の結果を次の学習の結果に生かすという方法です。

LightGBMの主なメリットは下記の通りです。
・実行スピードが他の手法(同じく勾配ブースティング決定木の一種であるXGboostや、決定木以外のニューラルネット系の手法)と比較して速い。
・欠損値やカテゴリ変数を含んだままでも、モデルを学習させることができる。
それでは実際に学習させてみます。
これも提出してみます。

ロジスティック回帰よりもスコアは向上しました。LightGBMは最近開発されたアルゴリズムなので精度がいいということですね。
アンサンブル学習
様々な予測モデルを組み合わせて一つのモデルとする手法をアンサンブルといいます。
複数のモデルを用意して予測結果の多数決をすることで、単体のモデルよりも精度が良くなります。
やり方は非常に簡単で単純に予測結果の値を足してモデルの数で割るだけです。
今回はLightGBMとロジスティック回帰の平均を求めますが、本来は精度の良いモデルに重みをつけることが多いです。
結果はこんな感じになりました。

なんだよ・・・結構当たんじゃねぇか・・・
アンサンブル学習は割とスコアが向上しやすい気がします。もちろんより多くの学習モデルでアンサンブルすればよりスコアは向上するので、選択肢を増やすという意味でもモデルは沢山知っているほうがいいでしょう。
スコアを上げる方法
一通り予測を行ったのでよりスコアを上げる方法を考えてみます。技術的なこと何も書いてないと思ったので初心者がいろいろ考えてみました。正直内容には自信がないので軽い気持ちで見てください。
・・・スコアを上げる方法は(少なくとも)3つあります。
・学習モデルのハイパーパラメータを調整する
・複数のモデルでアンサンブル学習をする
・データの前処理を行う
ハイパーパラメータを調整するというのはモデルの変数を変えることです。LightGBMであれば探索の回数や条件分岐の層の数にあたるのですが、これはあんまり効果が出にくい印象です。Oputunaというハイパーパラメータを最適化してくれるライブラリもあるのですが、時間がかかるわりにはスコアは向上しにくいです。ただ、ニューラルネットのような層の数で性能の良さが大きく変わるモデルであればハイパーパラメータを考えることは重要です。
複数のモデルでアンサンブル学習するというのはより多くのモデルで値を予測して、多数決して値を決めようということです。後述しますが、このデータは前処理が難しいので、一番効果があるように思います。注意点があるとすれば同じアルゴリズムで動くモデルでアンサンブル学習してもあまり効果がないことでしょうか。決定木の一種であるLightGBMとXGboostでアンサンブルしてもほとんど意味がありません。今回扱っているデータは説明変数が量的で目的変数が質的である他クラス分類問題なので、ニューラルネット、基底関数、カーネル法等を試してみると良さそうです。
データの前処理というのはモデルに与えるデータを整形することです。不定値(Null値)を平均値で埋めたり外れ値を除去したりといったことが挙げられるのですが、
これが非常に南海ホークス。というのもデータによって値が全然が違うので単純にコードをコピペするだけじゃうまくいかないんですよね。そのうえこのデータは不定値も質的変数もないためデータを改竄することが難しい。外れ値は今回予測するものが所属確率なので、外れ値にもちゃんと意味はある。そう考えたら何をすればいいのか全然わからなくなりました。
まぁそんなわけで個人的な見解としてはアンサンブル学習を試すのが一番良さそうという結論になりました。本当にそうなのかは分かりません。一緒にやる人がいないので
私はこの問題について真に驚くべき解法を発見したが、ここに記すには余白が狭すぎる。(一度言ってみたかった)
終わりに
完走した感想ですがコードの知識が全然足りないなーと。本当はデータの前処理であれやこれやして最後にね、簡単でしょとか言いたかったんですがpandasの知識がなさすぎて断念しました。アルゴリズムの勉強とかも重要なんですがコードが書けなきゃ意味がないというのを痛感しました。
肝心のマウスの件なんですが2月の大会?までには完成させたいと思ってます。マウスを作れば、「え、彼女作ってないやつおりゅ?」とマウントをとってくる相手に対して逆に「え、マウス作ってないやるおりゅ?」とカウンターをキメることができるのでそれをモチベに頑張ります。
明日はATさんの「まじ卍」です。(え?)
実際に見ないと内容が分かりませんね。
というわけで明日の記事は単位を質に入れてでも見ましょう。
最後まで読んでいただきありがとうございました。